Developers can use synthetic data to train machine learning models for computer vision applications such as robotics, noted NVIDIA Corp. this week. Researchers at the Santa Clara, Calif.-based company introduced a structured domain randomization system within Omniverse Replicator that can help developers train and refine their models with synthetic data.
Omniverse Replicator is a software development kit (SDK) built on the NVIDIA Omniverse platform that enables developers to build custom tools and workflows, said deep learning solutions architect Kshitiz Gupta and solutions architect Nyla Worker.
“The NVIDIA Isaac Sim development team leveraged Omniverse Replicator SDK to build Isaac Replicator, a robotics-specific synthetic data-generation toolkit, exposed within the Isaac Sim app,” they wrote in a blog post.
“As roboticists leverage AI to create better perception stacks for their robots, they will increasingly rely on synthetic data,” said Gerard Andrews, senior product marketing manager for robotics at NVIDIA. “In this blog, we give a technical walkthrough of how to generate a quality dataset to help spot recognize doors in an indoor office environment.”
“Synthetic data will increasingly become a critical part of the workflow of anyone creating AI models for robots,” he told Robotics 24/7. “Domain randomization is the superpower that adds the data diversity to training datasets to ensure that models generalize to their real-world environments.”
Trimble and Boston Dynamics turn to synthetic data
NVIDIA's team explored using synthetic data generated from synthetic environments for a recent project, explained Gupta and Worker. Machine controls provider Trimble plans to deploy Boston Dynamics' Spot quadruped robot in a variety of indoor in a variety of indoor settings and construction environments.
However, Trimble needed to develop a cost-effective and reliable workflow to train machine learning (ML) perception models so that Spot could operate autonomously in different indoor settings.
By generating data from a synthetic indoor environment using structured domain randomization (DR) within Isaac Replicator, developers can train an off-the-shelf object-detection model to detect doors in the real indoor environment.

Mind the Sim2Real domain gap
Given that synthetic data sets are generated using simulation, it is critical to close the gaps between simulation and the real world, said NVIDIA. This gap is called the domain gap, which can be divided into two pieces:
- The appearance gap is the pixel-level differences between two images. These differences can be a result of differences in object detail, materials, or in the case of synthetic data, differences in the capabilities of the rendering system used.
- The content gap refers to the difference between the domains. This includes factors like the number of objects in the scene, their diversity of type and placement, and similar contextual information.
A tool for overcoming these domain gaps is domain randomization. It can increase the size of the domain generated for a synthetic dataset to try to include the range that best matches reality, including “long tail” anomalies.
“By generating a wider range of data, we might find that a neural network could learn to better generalize across the full scope of the problem,” said Worker and Gupta.
The appearance gap can be further closed with high-fidelity 3D assets and ray tracing or path tracing-based rendering, using physically based materials such as those defined with the Material Definition Language (MDL). Validated sensor models and DR of their parameters can also help here.
How to set a synthetic scene
The building information model (BIM) of an indoor scene was imported into Isaac Sim from Trimble SketchUp through the NVIDIA Omniverse SketchUp Connector. However, there was an obvious gap between simulation and reality.
This is Trimble_DR_v1.1.usd, with the starting indoor scene after it was imported into Isaac Sim from Trimble SketchUp shown below.
To close the appearance gap, the researchers added some textures and materials using NVIDIA MDL to the doors, walls, and ceilings to make the scene look more realistic.
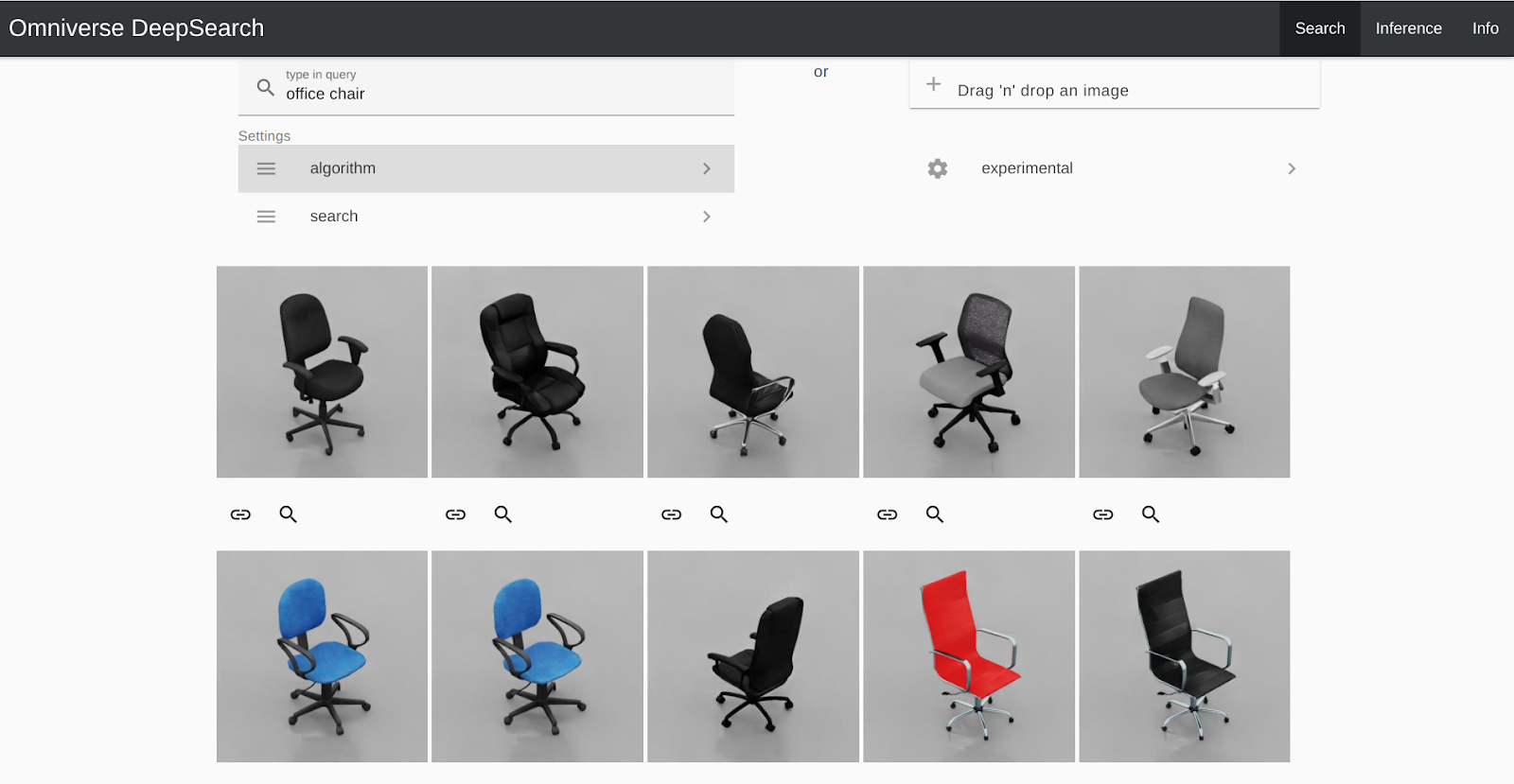
“To close the content gap between simulation and reality, we added props such as desks, office chairs, computer devices, and cardboard boxes to the scene through Omniverse DeepSearch, an AI-enabled service,” said Gupta and Worker. “Omniverse DeepSearch enables you to use natural language inputs and imagery for searching through the entire catalog of untagged 3D assets, objects, and characters.”
These assets are publicly available in NVIDIA Omniverse.
The researchers also added ceiling lights to the scene. To capture the variety in door orientation, a DR) component was added to randomize the rotation of the doors, and Xform was used to simulate door hinges.
This enabled the doors to open, close, or stay ajar at different angles. The video below shows the resulting scene with all the props.
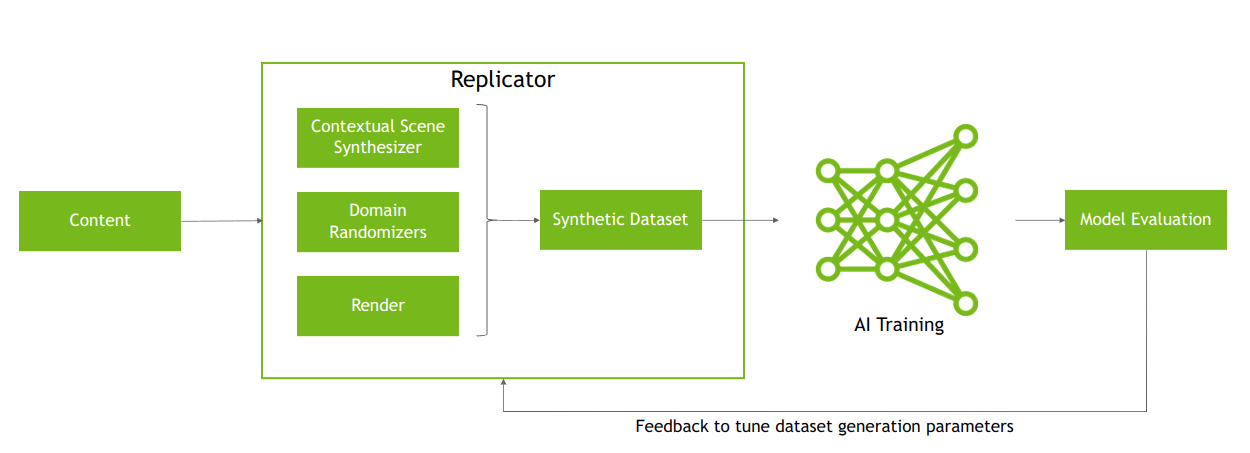
Synthetic Data Generation process begins
At this point, the iterative process of Synthetic Data Generation (SDG) was started, said NVIDIA. For the object-detection model, it used TAO Detectnet V2 with ResNet18 backbone for all the experiments.
All model hyperparameters, including batch size, learning rate, and dataset augmentation configuration parameters, were fixed constant at their default values.
“Instead of model hyperparameters, in synthetic data generation, we iteratively tune the dataset generation parameters,” explained Gupta and Worker.
The Trimble v1.3 scene contained 500 ray-traced images and environment props. It had no DR components except for door rotation, and door texture was held fixed. Training on this scene resulted in 5% average precision (AP) on the real test set of about 1,000 images.

Randomization helps overcome overfitting
As shown above, the model failed to detect doors adequately on most of the real images because it overfit to the texture of the door in simulation. The model’s poor performance on synthetic validation dataset with different textured doors confirmed this, the researchers said.
Another observation was that the lighting was held steady and constant in simulation, whereas in reality, there is a variety of lighting conditions.
To prevent overfitting to the texture of the doors, NVIDIA's team applied randomization to the door texture among 30 different wood-like textures. To vary the lighting, it also added DR over the ceiling lights to randomize the movement, intensity and color of lights.
Once the texture of the door was randomized, the researchers gave the model a learning signal on what makes a door besides its rectangular shape. To do so, they added realistic metallic door handles, kick plates, and door frames to all the doors in the scene.
Training on 500 images from this improved scene yielded 57% AP on the real test set. The indoor scene below includes DR components for door roation, texture, and color and movement of lights.
This model did better than before, but it was still making false-positive predictions about potted plants and QR codes on the walls in real test images. It also did poorly on the corridor images where multiple doors were lined up. And it had a lot of false positives in low-temperature lighting conditions, as shown below.
To make the model robust to noise like QR codes on walls, NVIDIA applied DR overtexture, which randomized the texture of the wall with different textures including QR codes and other synthetic textures. The researchers added a few potted plants to the scene. Since they already had a corridor in the synthetic scene, to generate synthetic data from it, they added two cameras along the corridor, along with ceiling lights.
In the test, NVIDIA added DR over light temperature, along with intensity, movement, and color to enable the model to better generalize in different lighting conditions.

“We also notice a variety of floors like shiny granite, carpet, and tiles in real images,” said Gupta and Worker. “To model these, we applied DR to randomize the material of the floor between different kinds of carpet, marble, tiles, and granite materials.”
“Similarly, we added a DR component to randomize the texture of the ceiling between different colors and different kinds of materials,” they recalled. “We also added a DR visibility component to randomly add a few carts in the corridor in simulation, hoping to minimize the model’s false positives over carts in real images.
Synthetic dataset of 4,000 images generated from this scene below got around 87% AP on the real test set by training only on synthetic data, thus achieving decent sim2real performance, claimed NVIDIA.

Synthetic data generation in Omniverse
Using Omniverse connectors, MDL, and easy-to-use tools like DeepSearch, it’s possible for ML engineers and data scientists with no background in 3D design to create synthetic scenes, said Worker and Gupta.
NVIDIA Isaac Replicator is intended to easily bridge the Sim2Real gap with structured domain randomization. Omniverse makes synthetic data generation accessible for bootstrapping perception-based ML projects, said the company.
“The approach presented here should be scalable, and it should be possible to increase the number of objects of interest and easily generate new synthetic data every time you want to detect additional new objects,” said the solutions architects.
Article topics
Email Sign Up


Related Simulation News




Related Companies
Related Resources










